常见问题#
如果在安装部署时出现了问题,可查阅本节获得修复方法,如仍未解决,需要联系开发者协助。
首先请按照配置项确认配置无误:
集群间免密配置:oushu 用户可以免密访问所有部署节点
所有部署节点操作系统配置:sysctl.conf 配置内容正确,且已经生效
所有部署节点操作系统配置:hosts 文件配置正确,并与 OushuDB/Magma 配置文件中使用的地址一致
所有数据库节点数据库配置文件:文件内格式正确,属性名称正确,属性值正确,topology.yaml 文件内容合规
所有Magma节点配置文件:文件内格式正确,属性名称正确,属性值正确,topology.yaml 文件内容合规
存储引擎配置:数据库配置了正确的访问地址与端口,并且配置了对应的权限认证(kerberos)
文件权限配置:数据库文件路径、配置路径、日志生成路径配置了正确权限与属主
其他的配置: 现有环境无历史版本数据库的控制数据残留、进程残留、文件残留。
OushuDB 初始化的工作流程如下:节点1执行初始化命令
初始化命令发送到所有master执行初始化操作
某个 master 节点与 Magma 通信初始化 OushuDB 元数据
数据库 master 节点初始化本地控制文件、参数与路径
数据库 master 节点启动
初始化命令发送到所有 segment 节点执行初始化操作
数据库 segment 节点初始化本地文件与参数
数据库 segment 节点启动
上述流程出现异常则会导致数据库初始化失败。
OushuDB 日志路径下一般有这些文件夹:admin, master, segment, vsc_catalog, vsc_default
admin 文件夹下包含了 OushuDB 与 Magma 启动、停止、创建、参数更新、重启的日志,其命名规则为[oushudb|magma]_[create|start|stop|init]_time.log,例如
oushudb_init_20221227.logmaster 文件夹下包含了 OushuDB main 节点运行时产生的日志文件。
segment 文件夹下包含了 OushuDB segment 节点运行时产生的日志文件。
vsc_catalog 文件夹下包含了 Magma 元数据集群节点运行时产生的日志文件。
vsc_default 文件夹下包含了 Magma 创建的数据存储集群 vsc_default 节点运行时产生的日志文件。
可以通过如下步骤检查收集错误日志:
检查初始化脚本的屏幕的运行输出,一些显而易见的错误或错误节点的名称会直接输出到屏幕上
登录对应的节点,检查其日志生成路径下 admin 文件夹内的日志,排查初始化、启动、重启、停止时异常,文件名称一般为:
oushudb\_[init|start|restart|stop]_time.log。检查日志生成路径下 master 文件夹内的日志,排查执行时异常
检查日志生成路径下 vsc_catalog 文件夹内的日志,排查 Magma 元数据集群执行异常,Magma在发生异常时会生成标记为fatal的文件,例如:
fatal-2022-12-27_140834.log检查日志生成路径下 segment 文件夹内的日志,检查 segment 启动时日常
通过上述的日志收集,我们至少能够明确初始化失败的流程位置与大致原因。
OushuDB初始化工作是 All or Nothing 的,因此如果在某次初始化失败后,需要将残留的数据(包括Magma)全部清理,方才可以继续尝试初始化。需要清理的内容有如下部分:
Magma 元数据集群所有节点的数据文件与日志文件
OushuDB 集群所有节点的数据文件与日志文件
存储引擎中已经创建完成的数据库目录,例如 hdfs 中的
/oushudb/default_filespace
清理完成后,依照初始化Magma,初始化OushuDB的顺序重新初始化。
一些常见的错误与输出以及可能的原因与解决方法:
catalog has not yet been initialized waiting for retry xxx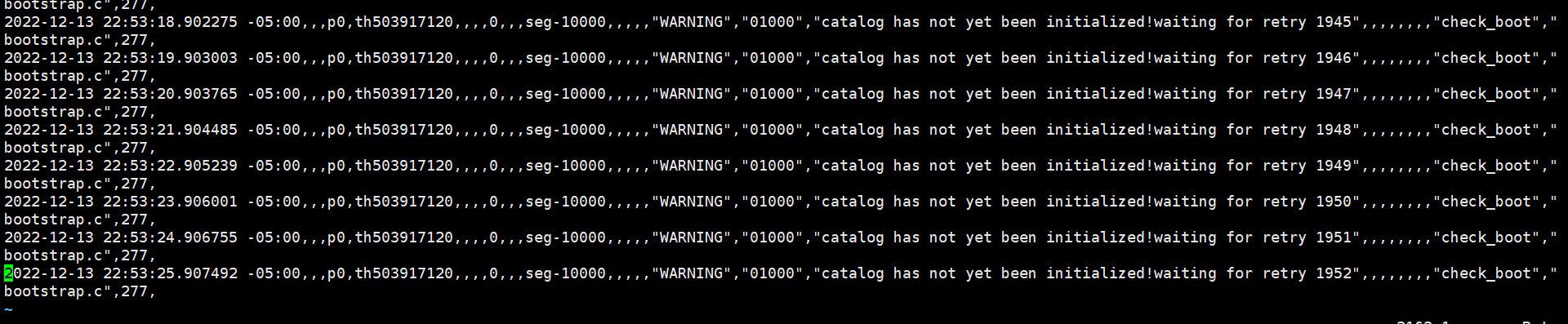
这是 Master 在 Magma 上创建元数据的过程,会等待数分钟,时间过长说明出现了问题。
检查
magma status,发现Magma 异常,检查FATAL_xxx.log 日志,发现Magma 错误:[Too many open files]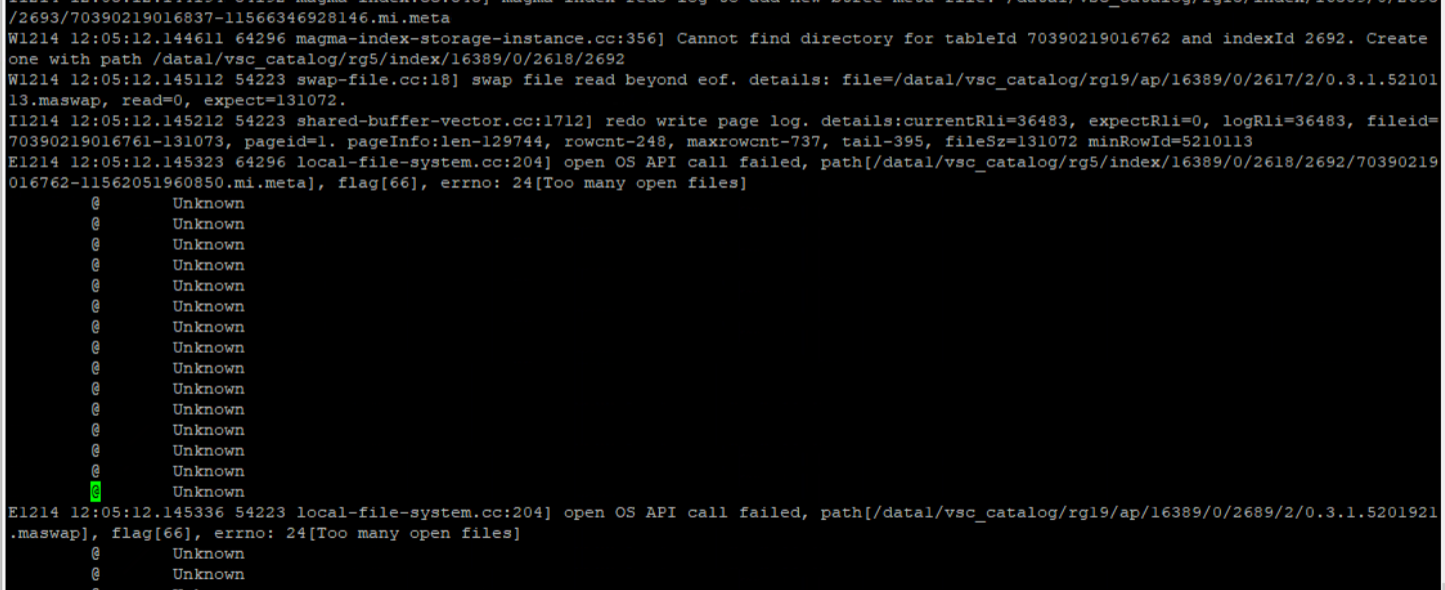
检查发现 HDFS 与 Magma 占用了太多打开文件数,最终通过增大操作系统打开文件数解决问题。
步骤:检查初始化脚本输出-> 检查初始化日志->检查 magma status -> 检查 magma fatal log -> 检查操作系统配置
共享内存无法创建
OushuDB 如果配置在内存资源比较受限的机器上,例如内存只有几个GB,需要调整OushuDB 配置项
max_jump_hash_map_num, 默认大小为512,可调整为8以便适应较小的系统内存lock file “”postmaster.pid”” already exists”,, Is another postmaster (PID xxx) running in …?
这是因为环境存在没有清除的文件导致的,有些锁文件或者标志文件被进程认为有正在运行的服务。 清理环境包括:清除进程、数据目录、日志目录、tmp文件下的lock锁文件(.s.PGSQL.5432.lock, .s.PGSQL.40000.lock)。
命令行部署OushuDB,注册到Skylab之后,使用工作簿报错
原因:命令行部署,缺少一个函数:has_table_privilege,通过可视化部署不存在这个问题,在部署的过程中会自动创建该函数。
解决方案: 用PSQL命令行连接刚刚部署的OushuDB,在每一个数据库(包括template1数据库)下执行如下SQL,创建这个函数。
create or replace function has_table_privilege(name,oid,char,oid,oid,aclitem[],text) returns bool as '$libdir/hornet', 'has_table_privilege_internal' language c stable;
如果集群由49xx系列升级到50xx,软件用户角色改变,需要主动删除 /tmp 目录下的锁文件:.s.PGSQL.5432.lock, .s.PGSQL.40000.lock